Reading notes: Triplets from different parents, CycleGAN, DiscoGAN, DualGAN
I saw these three GANs in differen places and found out that they are almost identical in model. The only difference among three papers is the experiment (maybe the high level motivation)
Task
The task is image-to-image translation with unpaired training set (as opposed to pix2pix which uses pairwise data). The motivation is hoping to find an unsupervised way to find image relations. As we discussed in the reading group, this task has no solid applications in vision (solid means that “could benefit the world” ?)
However, last year there was a machine translation paper called Dual learning. This seems to be more solid application (compared to horse2zebra). In machine translation, translation pairs are limited but the corpus in each language are enormous. That paper is discussing how could we use the unpaired corpus to help machine translation. Actually DualGAN drives their motivation from this paper, and the cycle consistency in these three papers are very similar to the idea in Dual Learning (however Dual Leanring is not cited in CycleGAN).
Instead, CycleGAN drives the motivation from ‘‘human’’. Because when people see a Monet painting, people can imagine what the scene should be like in real wourld. So an AI should be able to do that.
Models(The same for three papers):
A GAN normally has only one generator and one discriminator. The model has two generators and two discriminators. One generator transforms images of domain \(X\) to domain \(Y\) (denote as \(G\)), the other one do the opposite (denote as \(F\)). Two discriminators \(D_X\) and \(D_Y\) try to distinguish real and fake images in each domain (fake means transformed from another domain).
Cycle consistency (I use the term in CycleGAN) makes the transform meaningful. In principle if you transform X to Y and from Y back to X the final result should be similar to the input. So they force that by adding a penalty term which is the L1 distance between the original image and the one that is transformed back and forth.
\(\|F(G(X)) - X\|_1\) and \(\|G(F(Y)) - Y\|_1\)
This avoids the mode collapse. The authors (in DiscoGAN and CycleGAN) prove that this loss is necessary and also both terms are necessary.
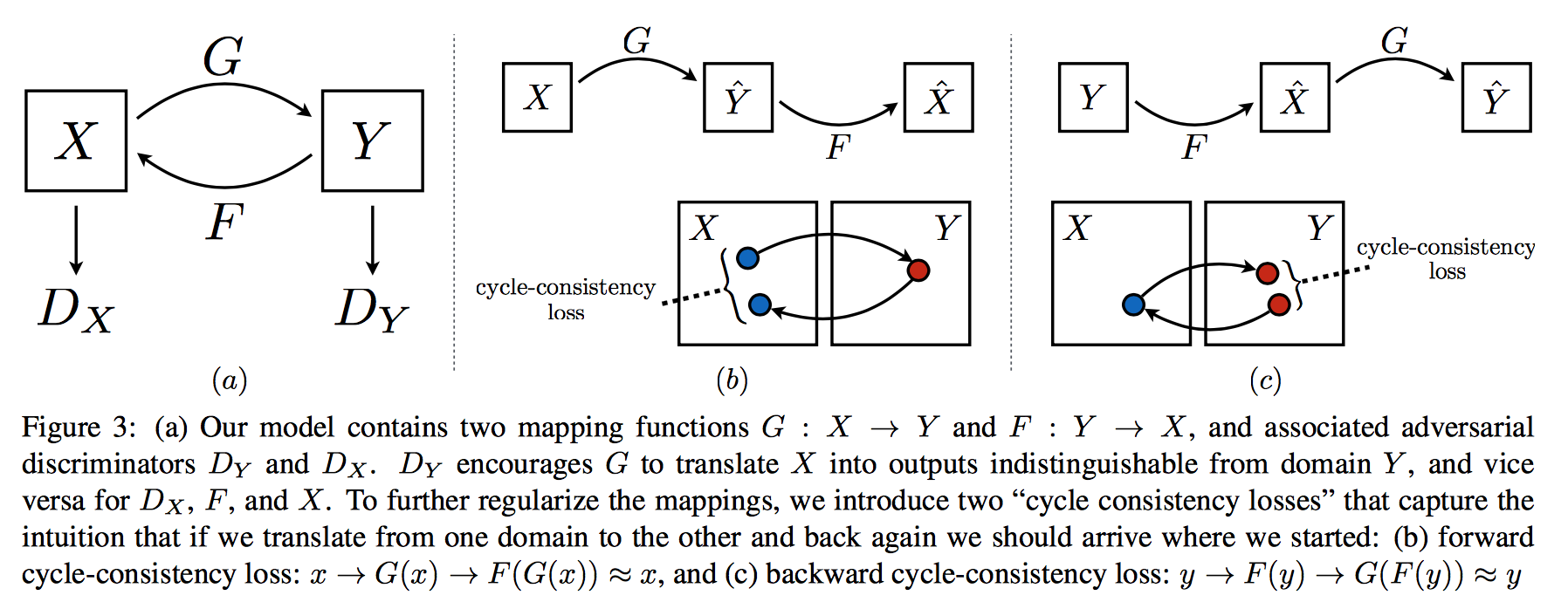
Illustration for the model
Network details:
CycleGAN:
The generator is the same as what in Perceptual losses for real-time style transfer and super-resolution. And they also use Instance Normalization. The discriminator is the same as pix2pix (PatchGAN on 70x70 patches). To stablize GAN training, they use Least square GAN and replay buffer. Unlike pix2pix, they don’t put any randomness in the model (no random z, no random dropout). The generator is more like deteministic “style tranfer” model than a conditional GAN generator. They use L1 distance for cycle consistency.
DualGAN:
The generator and discriminator are the same as pix2pix (No random noise z, randomness in dropout). Here they use WGAN for training and L1 for cycle consistency.
DiscoGAN: They use some conv layers, deconv layers with leaky relu activation as generator, and a convnet with leaky relu as discriminator. They use L2 for cycle consistency (It’s shown in their released code).
Experiments
CycleGAN: One main experiemnt is photos <-> labels of Cityscapes which is the same as in pix2pix. Photos are taken from cars, and the labels are the semantic segmentation of the photos. They use the same evaluation as in pix2pix. The CycleGAN is compared to CoGAN, BiGAN, pix2pix(as upper bound). CoGAN is a model which also works on unpaired images; the idea is to use two shared-weight generators to generate two images (in two domains) from one single random noise \(z\), the generated images should fool the discriminator in each domain. BiGAN originally is to find a function \(E\), which is the inverse function of generator \(G\), i.e. given a image, outputs what \(z\) generates the image. If you treat \(z\) as a image in another domain, then BiGAN can be used for this task.
The results show CycleGAN is superior to all the baselines. Of cause, there’s a large gap to pix2pix, but note that pix2pix is a fully supervised method and CycleGAN is a fully unsupervised method.
They further did ablation study on each component of the CycleGAN: without Cycle consistency; with only one direction of cycle consistency; without GAN loss and only cycle consitency. The result is in the following figure (the caption includes the analysis; in short, every component is essential).

CycleGAN Figure 7
Then they try some cool applications which are not evaluated because there are no ground truth pairs. They tried edge <-> shoes, horse <-> zebra, orange <-> apple, winter <-> summer, art <-> photo. These results are really cool.
DualGAN: Appilications: PHOTO-SKETCH, DAY-NIGHT, LABEL-FACADES, and AERIAL-MAPS. In some experiments, they even get better realness AMT score than pix2pix. This indicates that realness score is a bad score, because it only requires the model to generate realistic images regardless of the given input image.
DiscoGAN: I really like the toy experiment they did. They created two guassian mixture models as two domains, and learn a DiscoGAN, and they can visualize how baselines and their models behave differently in aligning the mixtures. One baseline is GAN, the genrator is trying to generate a output that is real in the another domain. Another baseline is GAN with forward consistency. They have shown that both baselines suffer from mode collapse.
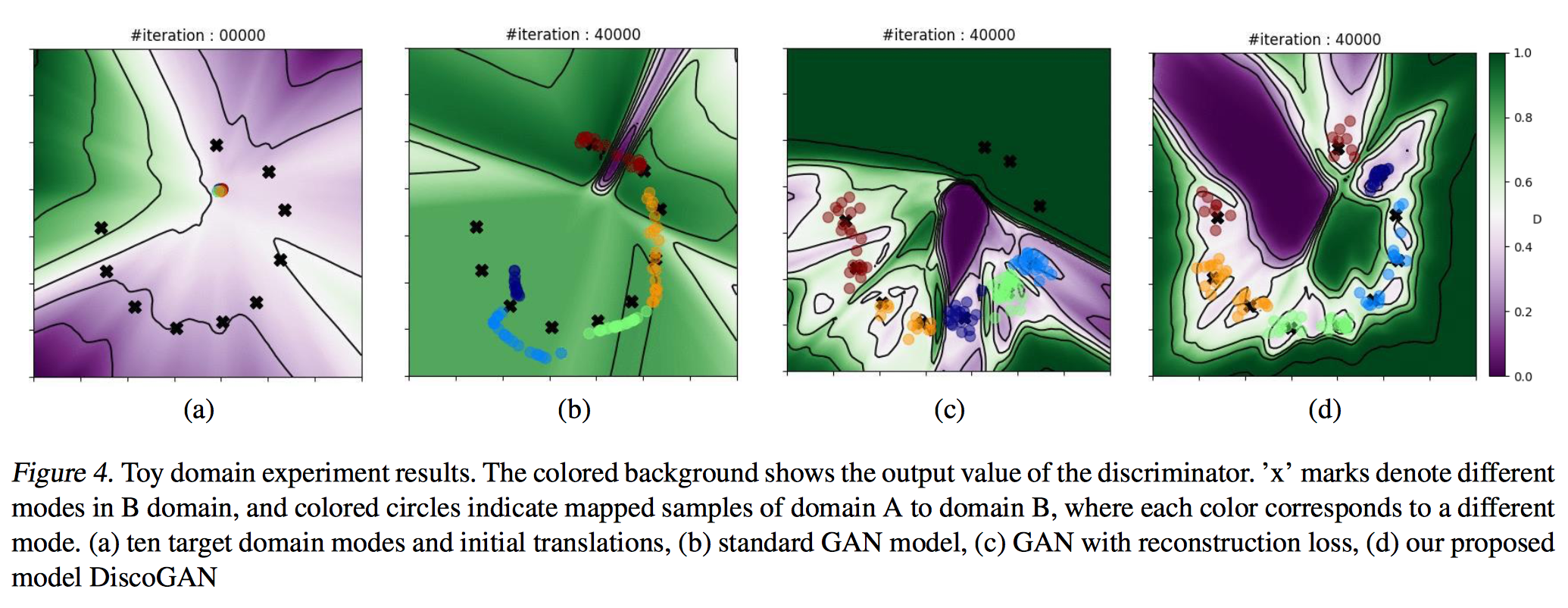
DiscoGAN Figure 4
And also they have a car to car toy experiment. Each domain has 3D car models with azimuth angles at 15 degrees intervals. You can see after the learning of different model, how the angles in two domains are mapped. The DiscoGAN get highly correlated mapping.
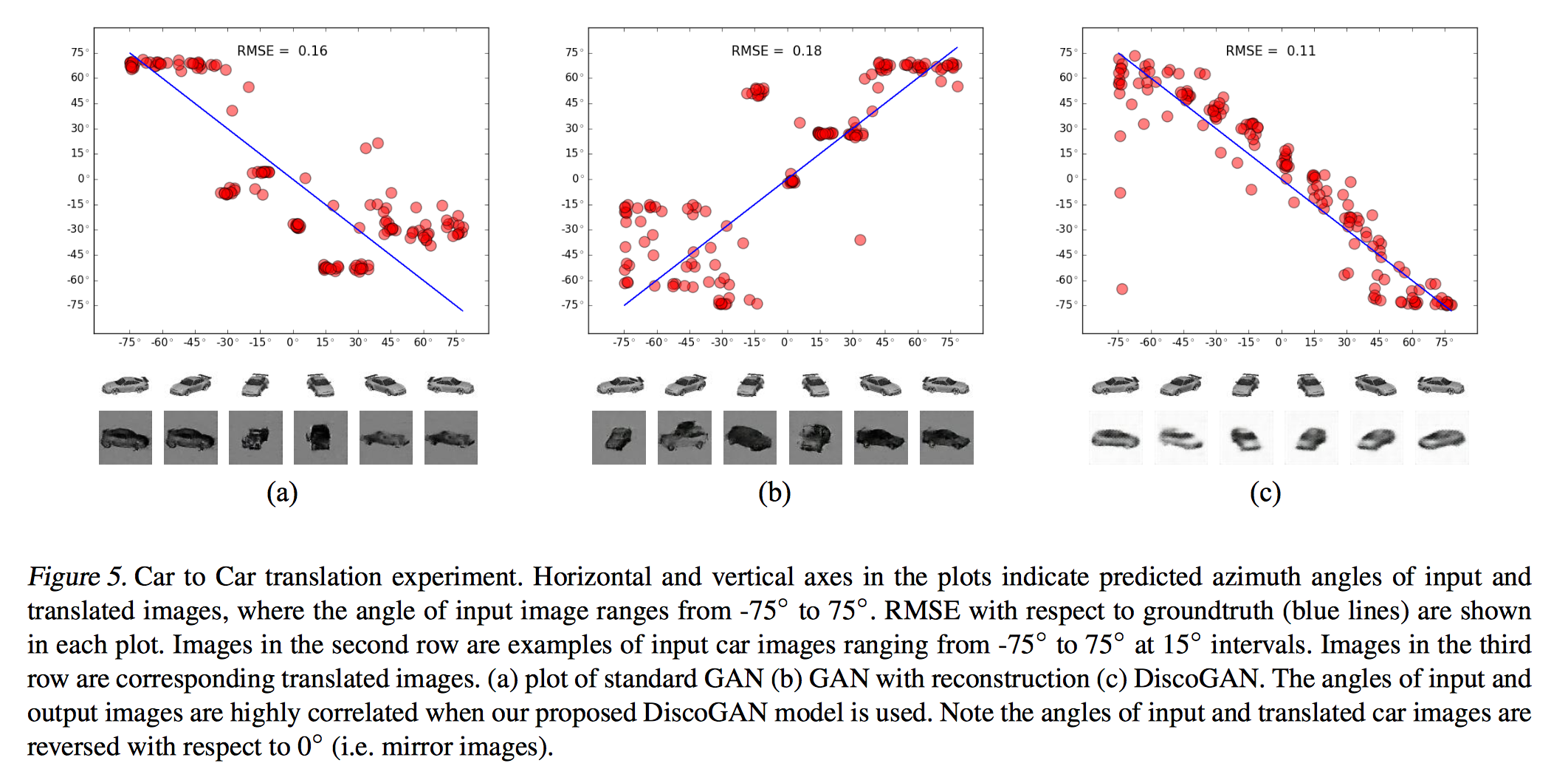
DiscoGAN Figure 5
They also did FACE to FACE, FACE CONVERSION(gender, hair color etc.), CHAIR TO CAR, CAR TO FACE, EDGES TO PHOTOS, HANDBAG TO SHOES, SHOES TO HANDBAG. The rest experiments are all qualitative, and are not as cool as what’s in CycleGAN.
Discussion
Observation: Wrong mapping. Because it’s fully unsupervised, they could find some “incorrect” mapping, like in photos to label, the building are sometimes labeled as tree. And in DualGAN figure 5(up there), the transform is learned to be flipping (which is actually reasonable).
Also, task like dog to cat is very hard, because it includes geometric changes. I doubt if it’s a reasonable task because it’s even hard for human to transform a dog to cat: maybe it’s possible to maintain the pose, but what about genre transform?
One more thing which is they didn’t discuss in the paper is what if you have two-cycle consistency. For example, \(F(G(F(G(x))))\) should be close to \(x\).