Reading notes: RL with unsupervised auxiliary tasks
This blog is about this paper from Deep mind. To be honest, it’s actually a quite simple paper. The idea is super naive but the result is surprisingly good.
The idea is we are only using part of the information provided by the environment to train the RL model, so how should we utilize these extra information. There are some previous works which design some auxiliary tasks like reconstructing the input or predicting the input change. In this paper, the author propose some other possible auxiliary tasks, and prove that these can significantly improve the speed and final reward of the model.
Methods
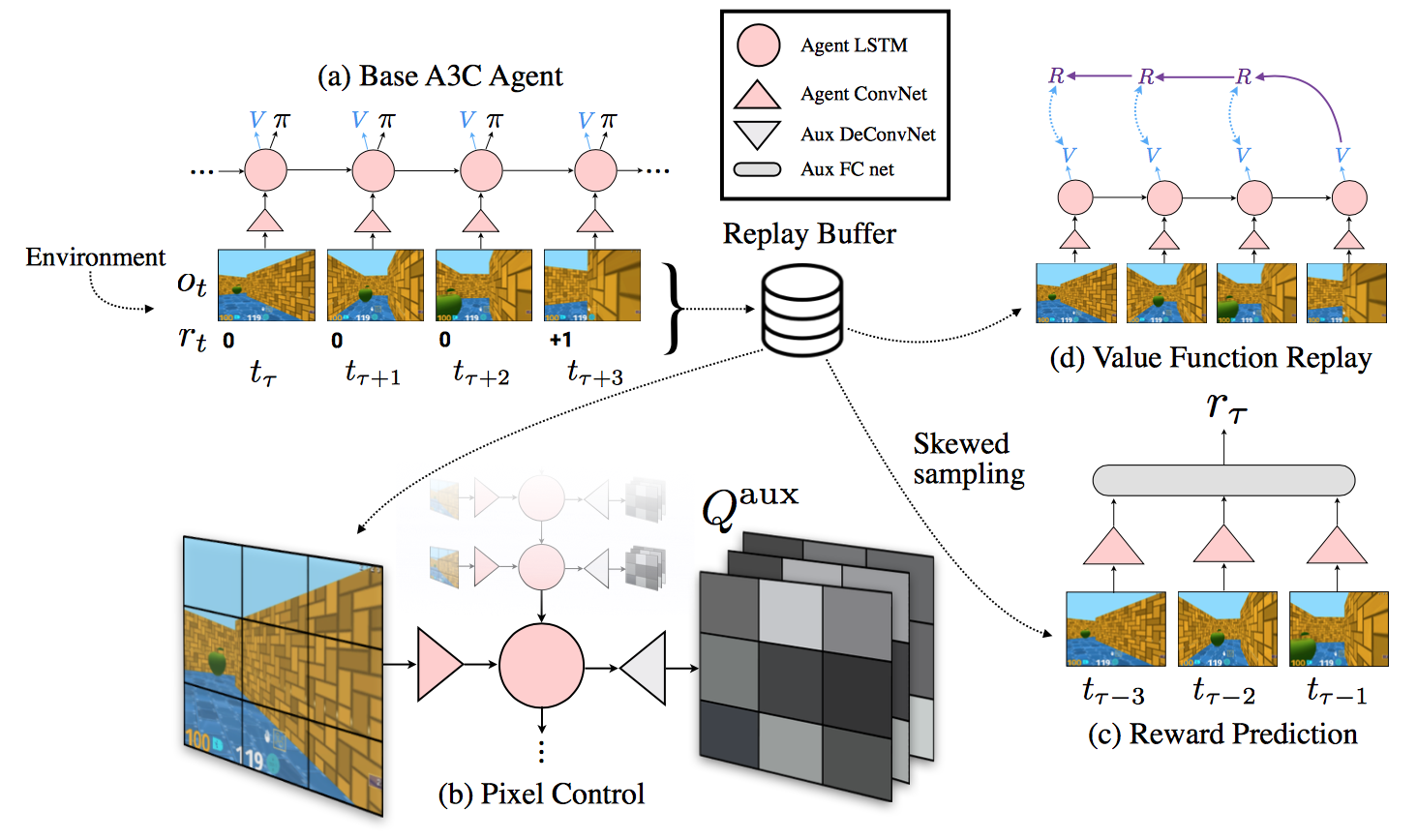
Over view of the model
(a) is the base agent is a CNN-LSTM agent trained on-policy with the A3C loss. The A3C agent is a CNN-LSTM model which output policy and value.
The auxiliary tasks are the (b) and (c). Let’s first talk about pixel control (b). The intuition is that:
Changes in the perceptual stream often correspond to important events in an enviroment. So they train a seperate policy (me: actually not) for maximally changing the pixels in each cell of an \(n \times n\) non-overlapping grid placed over the input image.
The value of pixel change is the average aboslute difference of each area. In the paper, they took the pixel change as a pseudo-reward, which they want the policy to take the move that maximize the pixel change; the equation one in the paper is saying this. However, they further turn the reward to the mean square error of value function. (It’s not maximizing the rewards at all. Will talk about it later.)
So they have a network which predicts the pixel change at each area given the state and action. The objective is the same as most Q-learning; they use a nature DQN with 20 step. The network for pixel control shares the CNN and LSTM with the base A3C model, and has its additional independent deconv layers.
They also mentioned briefly about feature control, which tries to maximize the features in a certain layer. There were not many results on this, but in the rebuttal on openreview, it seems they can achieve similar result as pixel control.
The second auxiliary task is reward prediction: given three recent frames, the network must predict the reward that will be obtained in the next unobserved timestep. The idea is to use the onset of reward as an addtional information. There are three classes: positive, negative, no reward. To reduce the long term information, the only use the concatenation of the CNN feature from previous three frames (Note that LSTM contains long term information). The CNN is shared with A3C.
To train a meaningful classifier , they skew the examples so that the no reward samples have only 50% among the training samples. They also claim reward prediction has less bias to the policy. You can feel like the appearance of reward is kind of less dependent on policy.
Another important thing is exprience replay. They use experience replay to train the pixel control and reward prediction. Here let’s talk about the problem in pixel control. Aparrently the Q function of pixel control is trained from the replay data which is the result executed by the A3C policy. However the assumption of the Q function(the Bellford function) is assuming reward is obtained from the \(\pi_c = \max_aQ_c(s,a)\). So it’s kind of wierd to say this update is valid. And definitely it’s not maximizing the pixel control reward, because the pixel control policy is never used. The pixel control is only used for representation learning.
They also use the reward prediction to update the value function. (Note that the Q value is also updated during the A3C.) I guess exprience replay makes it more stable and also faster to get the “True” value function.
Experiment
Although there are some unclear points in the methods. Their results are actually super good.
Adding these auxiliary tasks, the system is faster to train and also can achieve better result in most cases. Especially on Labyrinth, the pixel control can help a lot.
Their hyperparamters are relatively simple, and they did some hyperparameter searching. The results shows their model is more robust than normal A3C.