Reading notes: Progressive NN + Pathnet + EWC
There has been several paper published by Deepmind regarding sequential learning: Progressive Neural Networks, PathNet: Evolution Channels Gradient Descent in Super Neural Networks, Overcoming catastrophic forgetting in neural networks.
Progressive NN was like already one year old; I think they first presented it on RSS workshop, and then published it in last year NIPS. However, it’s important because it’s a pioneer work with rgard to the latter two paper. The latter two are quite recent papers, and were released concurrently; part of the ideas in these two are actually similar. Let’s see these three paper.
Problem
What’s the main problem considered in these three paper? Consider playing games, if you can play Call of Duty well, you could probably can quickly nail Overwatch, because they are both FPS games (Yes, I play overwatch, although I don’t play well). So people have the ability to transfer the knowledge from one problem to the other, and also still don’t forget the first task. It’s called continual learning or sequence learning. There are two subproblems: first, how to transfer the knowledge; second, how to remember all the tasks.
Progressive NN
Progressive NN is the first paper I know that Deepmind does for this task. The idea here is to not forget the network for task1 and also could reuse that network for task2.
To not forget, they did a simple thing: just keep the network for previous tasks, and create a new one for the new task. To reuse the previous network, they feed the input to all the previous output, and the output of each layer of each previous networks are fused into the current new network.
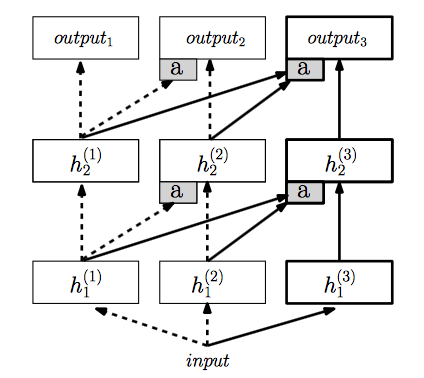
Progressive net
For every new task, they create a new column of network, and fuse the output of previous columns to the current one.
If the low level features of two tasks have similar modality, it’s quite possible that the earlier layer of the current task network is hardly used in the final prediction; the network could learn to only use the feature from previous networks.
However, one major problem for this method is, they can only use the lower layer of the previous networks; there’s no way to have its own lower layers and use the higher layer of pervious task, because the higher layer of pervious task will not receive the output of the current task network.
PathNet
Pathnet is a generalization of progressive nn.
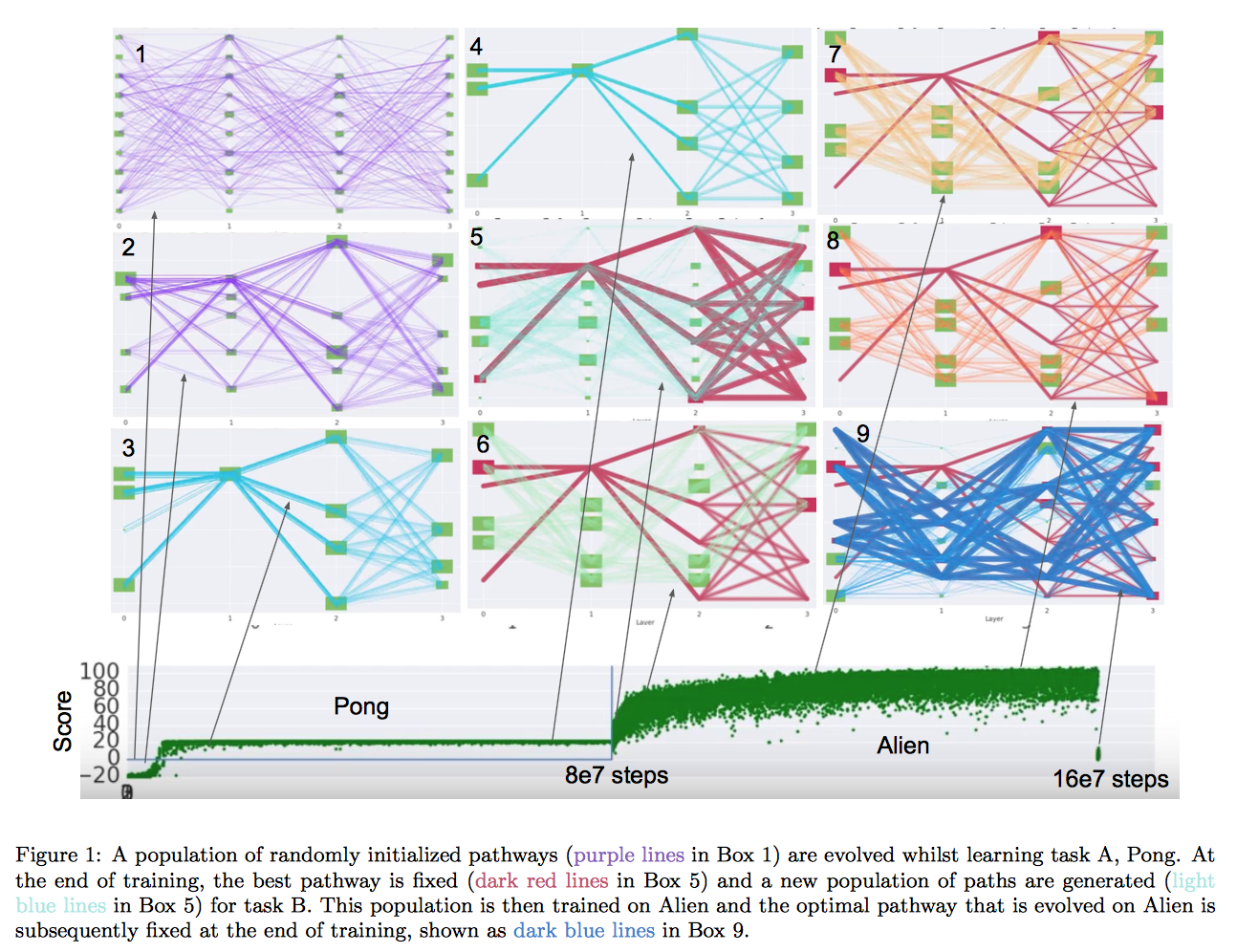
PathNet
You can regard each layer in the network as a LEGO blocks (green blocks in the figure), and building a network is to build blocks. The idea of pathnet is to reuse blocks.
At first, for each layer, we have N candidates modules; for each potential network, you can k modules at each layer. Then we randomly connected these modules to build multiple networks. After training for several episodes, we use genetic algorithm to eliminate bad configureations and mutate the good configurations, and train them further. In the end, we can get one best path.(1-4 in the figure)
Note that, this algorithm can be a standalone algorithm for a task.
So how could we use this alogrithm for continual learning? After training for the first task, we fix all the parameters of modules which appear in the path for the first task, and reinitialize all the other modules, and train similarly for task 2; the only difference is some modules are fixed. (5-9 in the figure)
You can see that, it’s quite similar to progressive network. Instead of columns, they have different path. In this formulation, one can have its only low-level feature extractor, but share the high-level semantic network.
EWC
EWC has a similar idea to pathnet: we should keep the parameters trained for previous tasks; however EWC(elastic weight consolidation) keep them elasticly.
(One thing need to mention beforehead: EWC is using one single newtork for multiple tasks)
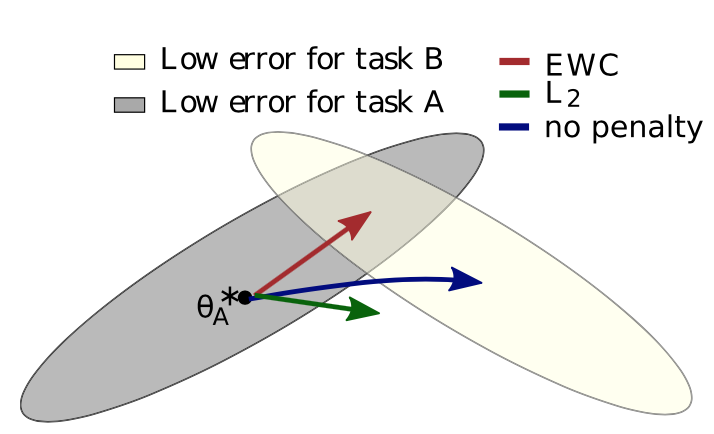
EWC
The most naive way to do continual learning is, train a network for task1 and finetune on taks2 (blue in the figure). In this way you basically forget how to do task1.
Then, you think, how should we put constraints on finetuning; what about forcing the paramters not leaving too much from the original parameters? This is L2 regularization(green in the figure) But this still doesn’t work well.
Then the next thought is, for task1, some of the parameters are actually not important. So the idea becomes, not changing the important parameters too much, but only updating the unimportant paramters(read in the figure). This is exactly the algorithm in this paper. You could think of it in this way, the important paramters for previous tasks have low learning rate when training for the current task, and vice versa. The importance is measured by the fisher infomation (the second derivative of the loss).
The did some analysis on the choise of importance. Using fisher information has good precision but low recall, because they are not considering pairwise relation.